
A pergunta mais desconfortável que um arquiteto pode receber depois de uma migração para serverless é simples: por que cada deploy precisa de coordenação entre quatro times agora? A resposta técnica é difícil. A organizacional é pior, porque revela que a arquitetura prometeu autonomia entre times e entregou o oposto.
Isso não acontece por culpa de serverless. Acontece por falta de design de domínio. E o design que resolve isso tem mais de 20 anos: Domain-Driven Design.
O zoológico de Lambdas
Já vi esse cenário mais vezes do que gostaria. Time adota serverless, começa a criar funções, APIs, tabelas. Tudo funciona, o deploy é rápido, a conta da AWS está sob controle. Seis meses depois, tem 300 Lambdas, 15 APIs no API Gateway, eventos cruzando por todo lado no EventBridge, e ninguém consegue responder uma pergunta básica: “qual é a fronteira desse serviço?”
O que aconteceu é clássico: escalaram a infraestrutura sem escalar o design. Serverless facilita a criação de recursos como nenhum outro modelo. Tão fácil que, sem disciplina, você cria um monolito distribuído sem perceber. Cada Lambda é pequena e independente no papel, mas o conjunto é um emaranhado acoplado que nenhum diagrama de arquitetura consegue salvar.
E o acoplamento mais perigoso não é o óbvio. Quando uma Lambda do domínio de pagamento acessa diretamente a tabela DynamoDB do domínio de pedidos, você tem acoplamento nos dados. Não importa que são funções separadas, deploys independentes, stacks diferentes. O acoplamento está na camada de persistência, e é o tipo mais difícil de desfazer.
O que DDD tem a ver com serverless
Domain-Driven Design foi criado pelo Eric Evans em 2003 para software orientado a objetos. Os conceitos têm mais de duas décadas e foram pensados para um mundo bem diferente do serverless. Mas a essência do DDD, organizar software em torno do domínio do negócio e não da tecnologia, é o que falta na maioria dos projetos serverless que crescem além do trivial.
Em vez de organizar sua arquitetura por tipo de recurso (aqui ficam as Lambdas, ali os bancos, acolá as filas), você organiza por domínio de negócio. Pagamento é um domínio. Cliente é outro. Pedido é outro. Cada domínio tem suas fronteiras, seus dados, suas regras. E essas fronteiras são o que impedem que o crescimento vire desordem.
Na minha experiência, o que separa um projeto serverless que funciona bem em escala de um que vira pesadelo operacional são fronteiras claras entre domínios. Não importa se você usa SAM ou CDK, qual runtime roda na Lambda, ou quanto de IaC está automatizado. Se não tem um modelo de domínio que organize o sistema de uma forma que o negócio reconheça, a bagunça é questão de tempo.
De domínios a domain services
Vamos ao mapeamento prático. Pega um domínio de e-commerce. O domínio geral é “e-commerce”. Dentro dele, existem sub-domínios: Pedido, Pagamento, Cliente, Entrega, Estoque. No DDD, cada sub-domínio encapsula uma capacidade de negócio com suas próprias regras e dados.
No serverless, cada sub-domínio vira um domain service: um serviço completo e autônomo. Na AWS, isso tipicamente se materializa como um API Gateway como ponto de entrada, um conjunto de Lambdas implementando a lógica, um ou mais bancos de dados próprios (DynamoDB na maioria dos casos), e eventos publicados via EventBridge.
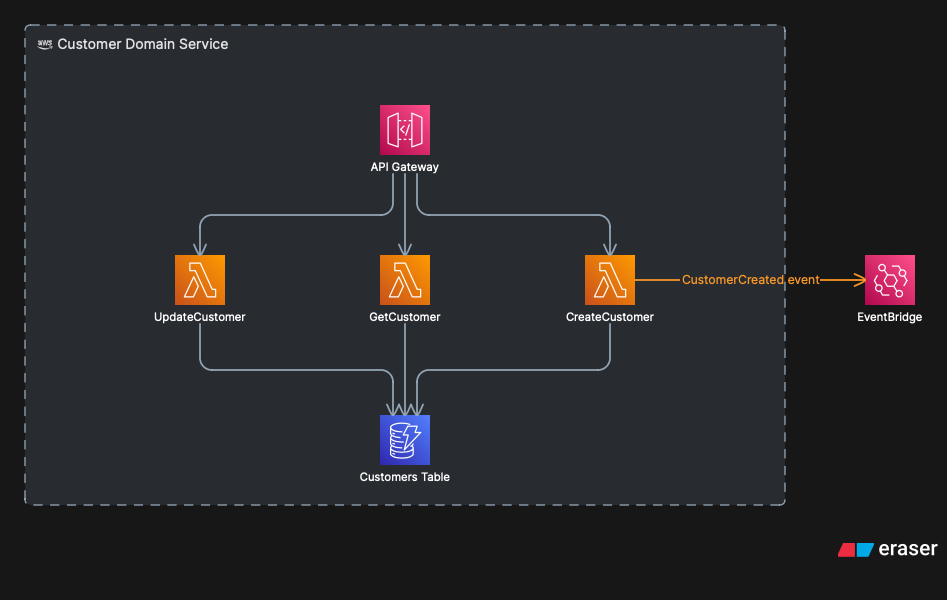
Anatomia de um domain service serverless: API Gateway como ponto de entrada, Lambdas e DynamoDB internos ao bounded context, e CustomerCreated event publicado externamente via EventBridge.
Dentro de cada domain service vivem um ou mais microserviços. No vocabulário do DDD, cada microserviço corresponde a um aggregate, uma unidade de consistência que encapsula uma entidade raiz e a lógica de negócio ao redor dela. O domain service de Cliente, por exemplo, pode ter um aggregate de “Cadastro” e outro de “Programa de Fidelidade”. Lambdas e tabelas próprias para cada um, mas dentro do mesmo domínio.
A regra fundamental: esses aggregates internos podem se comunicar entre si diretamente, via SQS, invocação direta, o que fizer sentido para o caso. Mas a comunicação com outros domain services passa obrigatoriamente pela API pública ou por domain events. Acesso direto ao banco de outro domínio é proibido. Sem exceção.
Na prática, cada entity (como “Customer”) tem um identificador imutável e vive dentro de um aggregate. Os value objects (como “Customer Address”) não têm identidade própria e existem como atributos vinculados à entity. No DynamoDB, isso pode ser modelado com adjacent list patterns, onde o value object é filho da entity raiz, referenciado por partition key. Parece detalhe de modelagem, mas essa distinção importa: ela define o que pode e o que não pode existir fora do contexto da entity principal.
Bounded context: a fronteira que faz serverless funcionar de verdade
Se existe um conceito de DDD que eu considero o mais importante para serverless, é bounded context.
Um bounded context é a fronteira ao redor de um domain service. Tudo que está dentro dessa fronteira usa o mesmo modelo de dados, a mesma linguagem, as mesmas regras. O que está fora não acessa diretamente: passa pela API ou consome eventos. Encapsulação de verdade, no nível de arquitetura.
No serverless da AWS, isso ganha uma tradução bem concreta. Cada bounded context pode ser uma conta AWS separada dentro de uma Organization (ou no mínimo um stack isolado), com seu próprio API Gateway, seus próprios bancos, suas próprias policies IAM. O time responsável pelo domínio controla tudo que está dentro. O que está fora é contrato público, documentado via OpenAPI, versionado, e estável. Outros times veem as interfaces de integração e pronto. Cognitive load reduzido.
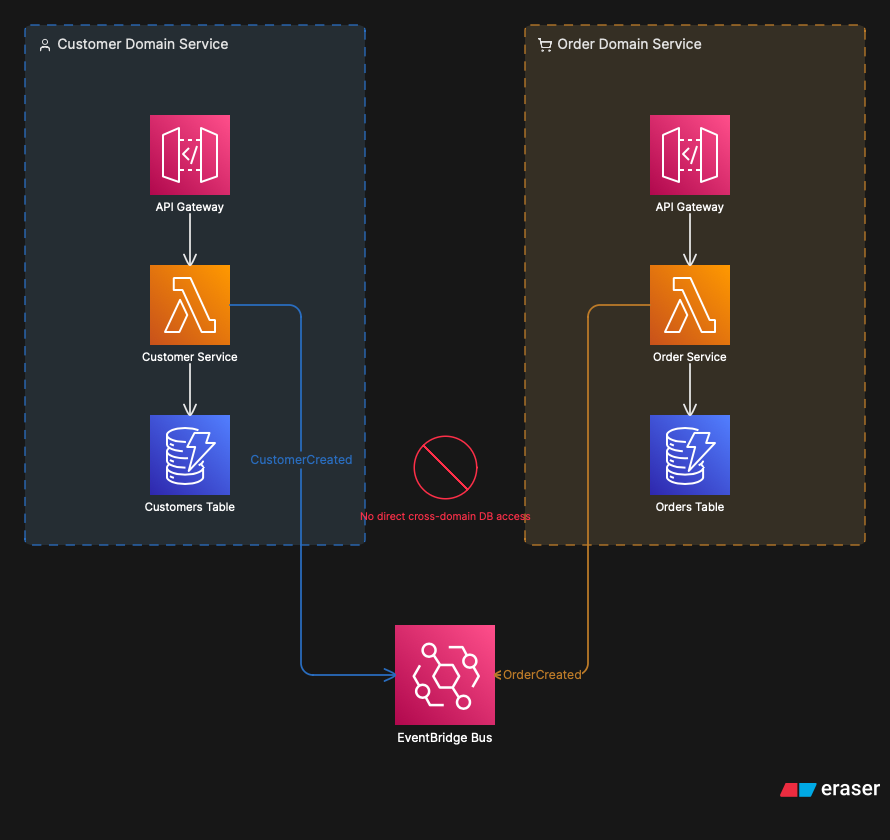
Dois bounded contexts isolados se comunicando exclusivamente via EventBridge. Acesso direto ao banco do domínio vizinho é proibido por design, não por política.
Particularmente falando, quando vi times aplicarem bounded contexts com disciplina, o ganho mais visível não foi técnico. Foi organizacional. Times pararam de pisar no pé uns dos outros, deploys deixaram de precisar de coordenação entre squads, e incidentes ficaram contidos dentro do domínio que falhou em vez de cascatear para o sistema inteiro. Essa é a independência que todo projeto de microservices promete, mas que sem bounded contexts claros simplesmente não acontece.
A ausência de bounded contexts é, na minha experiência, a razão número um pela qual projetos serverless viram monolitos distribuídos. A dependência que mata não é a de código, é a de dados. Qualquer mudança de schema no domínio vizinho vai quebrar silenciosamente o seu serviço, e você só descobre em produção.
Domain events e o EventBridge
Se bounded contexts definem as fronteiras, domain events são o mecanismo de comunicação entre elas. E na grande maioria dos casos, essa comunicação precisa ser assíncrona.
Um domain event é um fato que aconteceu no domínio. “Pagamento confirmado”, “Entrega cancelada”, coisas assim. O domain service que gerou o fato publica o evento. Quem precisa reagir, consome. O publicador não sabe e não precisa saber quem está do outro lado.
Na AWS, EventBridge faz esse papel. Cada domain service publica seus eventos em um bus (compartilhado ou dedicado, depende da organização), e outros domain services configuram regras para consumir o que lhes interessa. O serviço de Pagamento publica “PaymentConfirmed” e segue a vida. Se Pedido, Notificação e Analytics querem reagir a isso, o problema é deles. Pagamento não muda uma linha de código.
Isso resolve um problema real de coordenação entre times. Sem domain events, o caminho mais fácil são chamadas síncronas entre serviços. E chamadas síncronas criam cadeias de dependência frágeis onde a falha de um serviço cascateia para todos os que dependem dele. Com domain events, cada time controla seu domínio de ponta a ponta. Quando precisa adicionar um novo consumidor, basta criar uma nova regra no EventBridge. Nenhum deploy no serviço que publica.
Vale um ponto sobre a camada de experiência: nem todo evento precisa ser um domain event. Em um BFF (backend for frontend), um evento como “customer logged in” ou “customer sentiment is negative” pode fazer sentido como evento de aplicação, sem ser um evento de domínio. A distinção importa para não poluir o bus de domínio com eventos que são de interesse apenas da camada de apresentação.
Tipos de domínio: onde investir e onde ser pragmático
DDD classifica sub-domínios em três tipos. Essa classificação tem impacto direto em quanto esforço de design você coloca em cada domain service, e é uma das coisas mais úteis do DDD na prática.
Core é o que diferencia seu negócio dos concorrentes. Se você é um e-commerce, o motor de recomendação, o checkout otimizado, a gestão de estoque preditiva. Evans estima que o core domain entrega uns 20% do valor total do sistema com uns 5% do código e consome uns 80% do esforço. Aqui você coloca os melhores engenheiros, o design mais rigoroso, os testes mais completos. Se o core domain não estiver bem modelado com bounded contexts, aggregates e domain events claros, o resto não importa muito.
Supporting sustenta o core sem ser diferencial. Cadastro de clientes, gestão de endereços, histórico de compras. Precisa funcionar bem, mas não é o que ganha mercado. Serverless brilha aqui pela simplicidade: API Gateway, Lambda, DynamoDB, resolvido. Esses domínios são candidatos a serem desenvolvidos por times menos especializados ou terceirizados.
Generic é funcionalidade comoditizada. Envio de email, geração de fatura, autenticação. A regra é direta: compre antes de construir. SES para email, Cognito para auth, um SaaS para faturamento. Não gaste engenharia construindo o que já existe como commodity, seu diferencial competitivo não está aí.
Essa classificação ajuda a calibrar investimento. Nem todo domain service precisa de conta AWS dedicada, bounded context formal com EventBridge e API versionada. O service de “envio de email transacional” pode ser uma Lambda e um SES, sem aggregate, sem modelagem elaborada. Já o core domain merece todo o rigor, porque é dele que vem a vantagem competitiva.
Anti-corruption layers: protegendo seus domínios de sistemas legados
Um conceito de DDD que ganha relevância especial em cenários de migração é o anti-corruption layer. A ideia é simples: quando você precisa integrar um domain service novo com um sistema legado, coloca uma camada intermediária que traduz os modelos. O legado fala a língua dele, o domain service fala a dele, e o anti-corruption layer faz a tradução.
No mundo serverless da AWS, isso se implementa como um serviço de integração, geralmente na camada de experiência. Uma Lambda (ou um Step Function, dependendo da complexidade) que recebe o DTO do sistema legado, transforma no formato que o domain service espera, e repassa. O caminho inverso funciona igual.
Com isso, seu domain service novo não herda as decisões ruins do sistema antigo. E quando o legado for aposentado, você remove a camada de tradução sem tocar no domínio.
Ubiquitous language: o contrato que não é técnico
Um último conceito que vale mencionar: ubiquitous language. No DDD, é a prática de construir uma linguagem comum entre engenharia, produto e negócio. Todo mundo usa os mesmos termos para as mesmas coisas. “Pedido” significa a mesma coisa para o dev, para o PO e para o stakeholder.
Parece trivial, mas na prática a falta disso gera bugs de comunicação que viram bugs de software. Se o time de engenharia chama de “order” o que o negócio chama de “requisição”, e o banco chama de “request”, eventualmente alguém vai implementar a regra errada porque entendeu o conceito errado. Em organizações com operação em múltiplas regiões, onde domain services precisam ser internacionalizados e reutilizados, ter uma ubiquitous language definida globalmente não é luxo. É necessidade.
No serverless, isso se reflete nos nomes dos eventos no EventBridge, nos paths das APIs, nos nomes das tabelas, nos próprios nomes dos stacks. Se o domínio chama de “Customer”, o evento é “CustomerCreated”, a tabela é “Customers”, o path é “/customers”. Consistência entre código e negócio.
Quando DDD é over-engineering
Nem todo projeto serverless precisa de DDD. Se você tem um time pequeno, um domínio simples e 30 Lambdas, criar bounded contexts formais com domain events estruturados e contas AWS separadas por domínio vai mais atrapalhar do que ajudar.
DDD faz sentido quando múltiplos times trabalham no mesmo sistema e o domínio é complexo o suficiente para justificar decomposição. Na prática, isso aparece quando a organização passa de centenas de funções e precisa de independência real de deploy entre times.
Se você é um time de 3 pessoas construindo um MVP, foque em entregar. DDD entra depois, quando a complexidade justificar. O erro clássico é adotar cedo demais ou tarde demais. Cedo demais é burocracia que engessa sem entregar benefício. Tarde demais é tentar reorganizar centenas de funções acopladas que já estão em produção servindo clientes reais. Te garanto que a segunda opção dói muito mais que a primeira.
De volta à pergunta desconfortável
DDD não é novidade. Serverless também não. Mas juntar os dois é o que permite escalar serverless em enterprise sem perder o controle. Os conceitos do Evans, com mais de 20 anos e pensados para outro mundo, encaixam no modelo serverless de uma forma que eu não esperava quando comecei a aplicar. Sub-domínios se tornam domain services com APIs próprias, bounded contexts ganham forma concreta como contas AWS isoladas, aggregates se traduzem em microserviços encapsulados, e domain events fluem pelo EventBridge.
Se o seu projeto serverless está ficando difícil de entender e difícil de dividir entre times, é problema de design, não de tecnologia. Comece mapeando os sub-domínios do negócio junto com produto, defina bounded contexts claros com APIs versionadas, e garanta que toda comunicação entre domínios passe por eventos ou APIs públicas. Nunca por acesso direto aos dados de outro domínio.
Da próxima vez que perguntarem por que cada deploy precisa de coordenação entre quatro times, a resposta não vai ser técnica. Vai ser arquitetural. E o maior erro em arquitetura serverless nunca esteve em escolher Lambda em vez de container. Está em achar que serverless te isenta de fazer design de domínio.