
São dez da manhã, abriu a venda do show, e dois milhões de pessoas apertam refresh ao mesmo tempo para disputar cinquenta mil ingressos. Sua API escala. O Lambda escala. O API Gateway escala. E o banco de dados derrete. Não pelo volume total, o DynamoDB on-demand daria conta disso. Derrete porque todo mundo bate no mesmo item, o estoque daquele show, e uma única partição quente throttla enquanto o resto da tabela fica ocioso. O gargalo nunca foi a carga. Foi o hot key.
Já vi esse filme algumas vezes em sistemas de alta concorrência, e a reação típica do time é a errada: jogar mais réplica de leitura, mais connection pool, um cache na frente. Ajuda nas bordas, mas não resolve o problema estrutural. Quando o pico é de escrita, imprevisível e concentrado num único ponto, a resposta não é escalar o banco. É tirar o banco do caminho crítico. Esse é exatamente o problema que space-based architecture foi desenhada para resolver, e é dela que esse artigo trata, aplicada a serverless na AWS. Porque você vai acabar implementando o princípio dela de um jeito ou de outro. A escolha é se vai ser no design ou no meio do incidente.
O que é space-based architecture
O nome vem de tuple space, um conceito dos anos 80 da linguagem de coordenação Linda, depois popularizado por JavaSpaces: a ideia de uma memória compartilhada e distribuída onde processos leem e escrevem dados sem falar diretamente entre si. Mark Richards e Neal Ford catalogam essa arquitetura no Fundamentos de Arquitetura de Software, e ela é, sem exagero, a mais complexa do livro. Não é uma arquitetura que você adota por elegância. É uma que você adota porque esgotou as outras opções.
A premissa central é uma só: o banco de dados é o limite de escala da maioria dos sistemas. Você pode escalar o tier web e o tier de aplicação quase indefinidamente, mas em algum momento todo mundo converge para o mesmo banco, e ali a fila se forma. Space-based architecture resolve isso removendo o banco do fluxo transacional. Em vez de ler e escrever no banco de forma síncrona, a aplicação trabalha contra um in-memory data grid replicado, e a persistência acontece de forma assíncrona, por trás, sem bloquear nenhuma requisição.
Pensa numa cozinha de restaurante no auge do serviço de sexta à noite. Se cada garçom precisasse ir ao fornecedor buscar ingrediente a cada prato, a cozinha colapsava no primeiro rush. Não é assim que funciona. Antes do serviço, tudo é preparado no mise en place: os ingredientes ficam à mão, em memória, prontos. Durante o pico, ninguém toca o fornecedor. Cozinha-se em velocidade máxima a partir da prep station, e a reposição do estoque acontece depois, no ritmo de quem repõe, sem travar uma única comanda. O fornecedor é o banco de dados. O mise en place é o in-memory data grid. E quem repõe a despensa entre as comandas é o que a arquitetura chama de data pump.
Os componentes são bem definidos. O processing unit é a unidade de escala: contém a lógica de negócio e uma cópia em memória dos dados sobre os quais ela opera. Você escala subindo mais processing units, e cada um carrega seu próprio grid. Acima deles fica o virtualized middleware, que coordena tudo, e tem quatro partes. O messaging grid roteia as requisições para os processing units disponíveis e gerencia sessão. O data grid é o coração da arquitetura: replica os dados entre os processing units, de forma que quando um atualiza algo, os outros enxergam aquela mudança. O processing grid é opcional e orquestra requisições que envolvem múltiplos tipos de processing unit. E o deployment manager sobe e derruba processing units dinamicamente conforme a carga.
Fechando o ciclo, os data pumps enviam as atualizações de forma assíncrona e com entrega garantida para serem persistidas. Os data writers consomem o pump e escrevem no banco no ritmo que o banco aguenta. E os data readers fazem o caminho inverso: leem do banco para popular o grid em memória quando o sistema sobe ou quando todas as instâncias de um tipo de processing unit caem e a memória se perde.
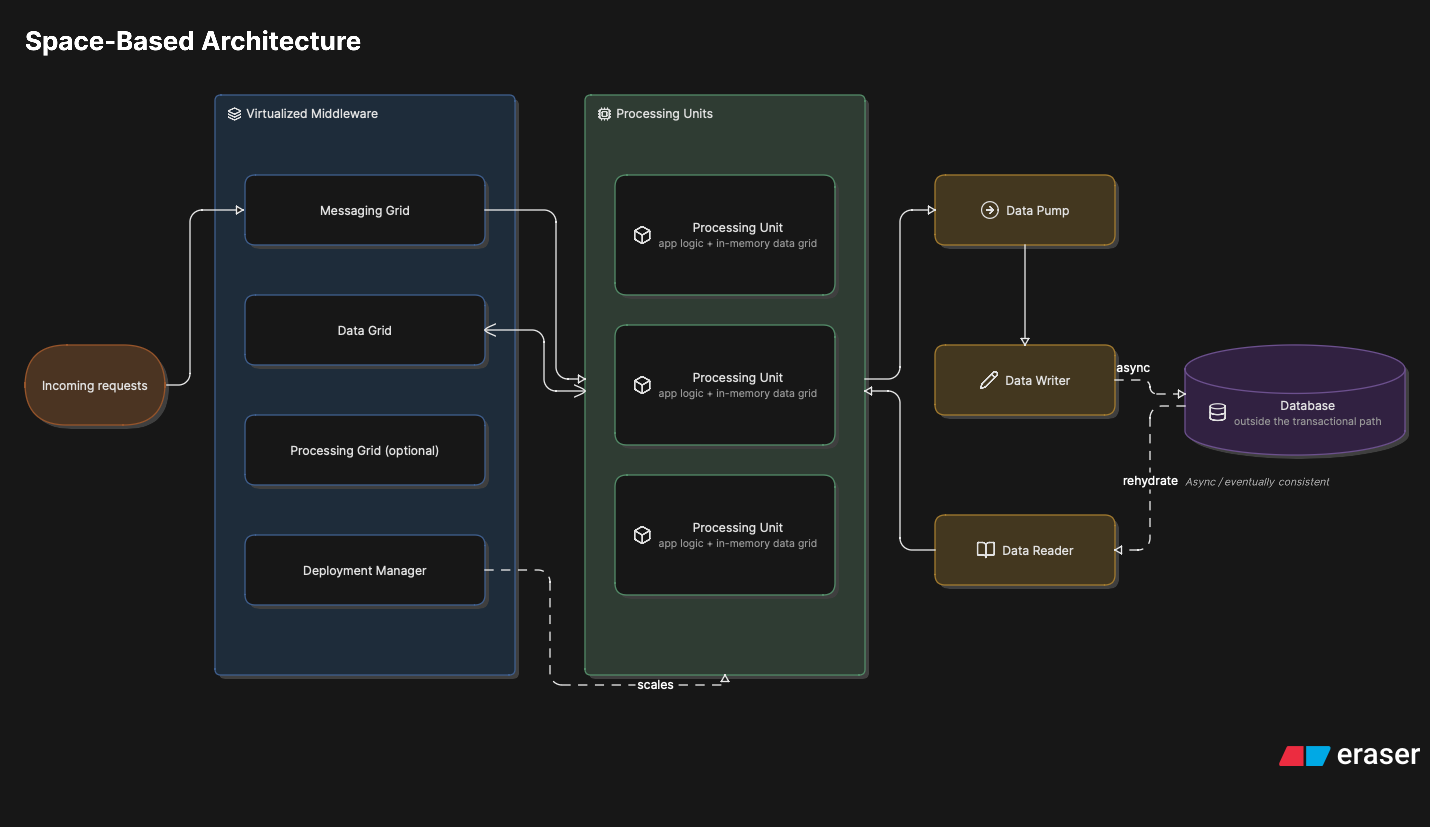
Anatomia da space-based architecture: processing units com data grid em memória, virtualized middleware coordenando, e o banco de dados fora do caminho transacional, alimentado de forma assíncrona pelos data pumps.
Vale entender uma decisão que define o comportamento da arquitetura: cache replicado versus cache distribuído. No cache replicado, cada processing unit tem uma cópia completa dos dados em memória, no próprio processo. É absurdamente rápido, acesso em nanossegundos, e resiliente, porque não depende de um servidor central. O preço é o tamanho, você está limitado pela memória de cada instância, e a colisão de dados, quando dois processing units atualizam o mesmo dado quase ao mesmo tempo. No cache distribuído, os dados ficam num servidor central e os processing units acessam pela rede. Cabe muito mais dado, mas você paga em latência e em um novo ponto de dependência. Guarda essa distinção, porque ela é o pivô de tudo quando a gente leva isso para serverless.
Por que isso importa e quando faz sentido
Space-based architecture não é de propósito geral. Ela existe para um perfil de carga muito específico: concorrência alta, variável e imprevisível, geralmente com escrita pesada. Venda de ingressos, flash sale de Black Friday, leilão online, apostas ao vivo, ranking de jogo em tempo real, qualquer evento viral onde o volume sai de centenas de requisições por minuto para centenas de milhares por segundo em questão de instantes.
O que torna esses casos especiais não é o volume médio, é a forma do pico. Um sistema com carga alta mas previsível você dimensiona e pronto. O problema é o pico que aparece sem aviso e dura segundos. Provisionar banco para o pico é caro e desperdiça o ano inteiro; não provisionar é aceitar que o sistema cai justamente no momento de maior valor para o negócio. Space-based architecture quebra esse trade-off: move a transação para a memória, absorve o pico onde ele dói e deixa a persistência drenar no ritmo possível.
Particularmente falando, esse é o ponto que separa quem entende a arquitetura de quem só decorou o diagrama: o objetivo nunca foi performance no geral, e sim absorver elasticidade extrema sem que o ponto mais lento do sistema, o banco, determine o teto. Se o seu sistema não tem esse perfil de carga, você não tem o problema que ela resolve, e ela vira peso morto. Volto nesse ponto no fim, porque é onde a maioria dos times erra.
Na prática, quase ninguém roda um in-memory data grid clássico, tipo GigaSpaces ou Hazelcast, como fonte da verdade hoje em dia. O que os sistemas de alta escala fazem é herdar o princípio. A Trip.com decrementa estoque no Redis primeiro e só depois persiste no MySQL de forma assíncrona via fila; aguenta mais de cem mil pedidos por minuto e picos de 45x sem o banco no caminho. A DraftKings, que tem um dos perfis de pico mais brutais que existem, o Super Bowl, mantém o ledger financeiro no Aurora MySQL, não num grid em memória: cerca de um milhão de operações por minuto, com sharding por consistent hashing no id do usuário e réplicas de leitura abaixo de 15ms. A lição é a mesma nos dois: o princípio da space-based architecture sobrevive, a implementação literal não.
A tensão entre space-based architecture e serverless
Por incrível que pareça, space-based architecture e serverless são, na forma canônica, quase incompatíveis. E isso precisa ficar claro antes de qualquer diagrama bonito.
A arquitetura clássica depende de processing units de vida longa, que seguram dados em memória, no próprio processo, e replicam esse estado entre si. Lambda é o oposto disso: stateless, efêmero, sem memória compartilhada entre invocações, podendo morrer a qualquer momento. Aquele cache replicado in-process que dá à space-based architecture seu acesso em nanossegundos simplesmente não existe num modelo onde a função não tem garantia nenhuma de continuidade. Você não tem onde manter o grid.
Então deixa eu ser direto: você não implementa space-based architecture literal em Lambda, você herda o princípio. Tirar o banco do caminho de escrita, atender a requisição contra uma camada rápida em memória, e persistir de forma assíncrona absorvendo o pico num buffer: isso é totalmente viável em serverless. O que muda é que aquele cache replicado in-process vira, obrigatoriamente, um cache distribuído externo, com um hop de rede no meio. Isso tem um custo de latência que eu detalho mais à frente. Mas, em troca, você ganha a elasticidade nativa de graça, que é justamente a parte mais difícil e cara de construir na space-based architecture tradicional.
Como construir isso em serverless na AWS
O mapeamento é direto, depois que você aceita que o “espaço” sai do processo e vira um serviço gerenciado. Cada componente da arquitetura clássica tem um equivalente:
| Componente clássico | Serviço AWS | Observação |
|---|---|---|
| Processing unit | Lambda | Lógica de negócio; lê e escreve no espaço, nunca no banco |
| Messaging grid | API Gateway | Roteamento; tem limite de RPS default, levante a cota antes do pico |
| Data grid (o espaço) | ElastiCache ou MemoryDB | Redis-compatible; cache ou durável |
| Processing grid (opcional) | Step Functions | Só quando um request orquestra vários tipos de PU; a maioria não precisa |
| Data pump | SQS ou Kinesis | Buffer assíncrono entre espaço e banco |
| Data writer | Lambda | Drena o pump e persiste no banco em lote |
| Data reader | Lambda | Reidrata o espaço a partir do banco |
| Deployment manager | Nativo da plataforma | Elasticidade do Lambda + scaling do Redis |
O espaço é a decisão central, e abre duas topologias bem diferentes. Para o papel de cache, ElastiCache no modo serverless resolve a maioria dos casos de absorção de pico, e resolve porque o que você precisa ali é throughput de acesso, não durabilidade: o working set do pico cabe em memória e o banco continua sendo a fonte da verdade. Quando o dado no próprio espaço não pode se perder, o caminho é MemoryDB, in-memory durável com transaction log multi-AZ, que pode ser a própria fonte de registro. A escolha consciente entre as duas muda o desenho inteiro: ou você usa ElastiCache como cache na frente do DynamoDB, com data pump e writer no meio, mais barato e com uma janela de perda; ou usa MemoryDB como espaço durável e elimina o pump, o writer e o DynamoDB inteiros, menos peças móveis, mais caro, escrita single-digit ms e sem modo serverless. A primeira é a default para absorver pico; a segunda faz sentido quando o dado é crítico e você quer menos partes para operar.
O data pump carrega uma sutileza que muita gente erra. Para pura absorção de pico, SQS Standard é o caminho mais simples e tem throughput praticamente ilimitado. Kinesis entra quando você precisa de ordenação por chave, replay, múltiplos consumidores ou agregação antes de gravar, que é o caso do write coalescing, juntar mil decrementos do mesmo SKU numa única escrita em vez de mil. E tem um detalhe que decide isso por você: decremento de estoque é comutativo, tirar um, tirar um, tirar um dá no mesmo em qualquer ordem, e é justamente por isso que SQS Standard sem ordenação basta para o contador. A ordenação do Kinesis só importa quando a operação não é comutativa, tipo transição de estado ou um campo last-write-wins. Se você já leu o que escrevi sobre domain events e EventBridge, a mecânica de desacoplar via fila vai soar familiar; aqui ela serve a outro fim, absorver pico, não isolar domínio.
O resto do mapeamento é mecânico. Os data writers são Lambdas consumindo o buffer e persistindo no DynamoDB em lote, no ritmo do banco. Os data readers repopulam o Redis a partir do DynamoDB quando há cache miss ou quando o sistema sobe do zero. E o deployment manager, aquele componente que na arquitetura clássica você teria que construir e operar para subir e descer processing units, aqui simplesmente não existe como código seu: é a elasticidade nativa do Lambda e o scaling gerenciado do Redis. Essa é a maior vitória da combinação.
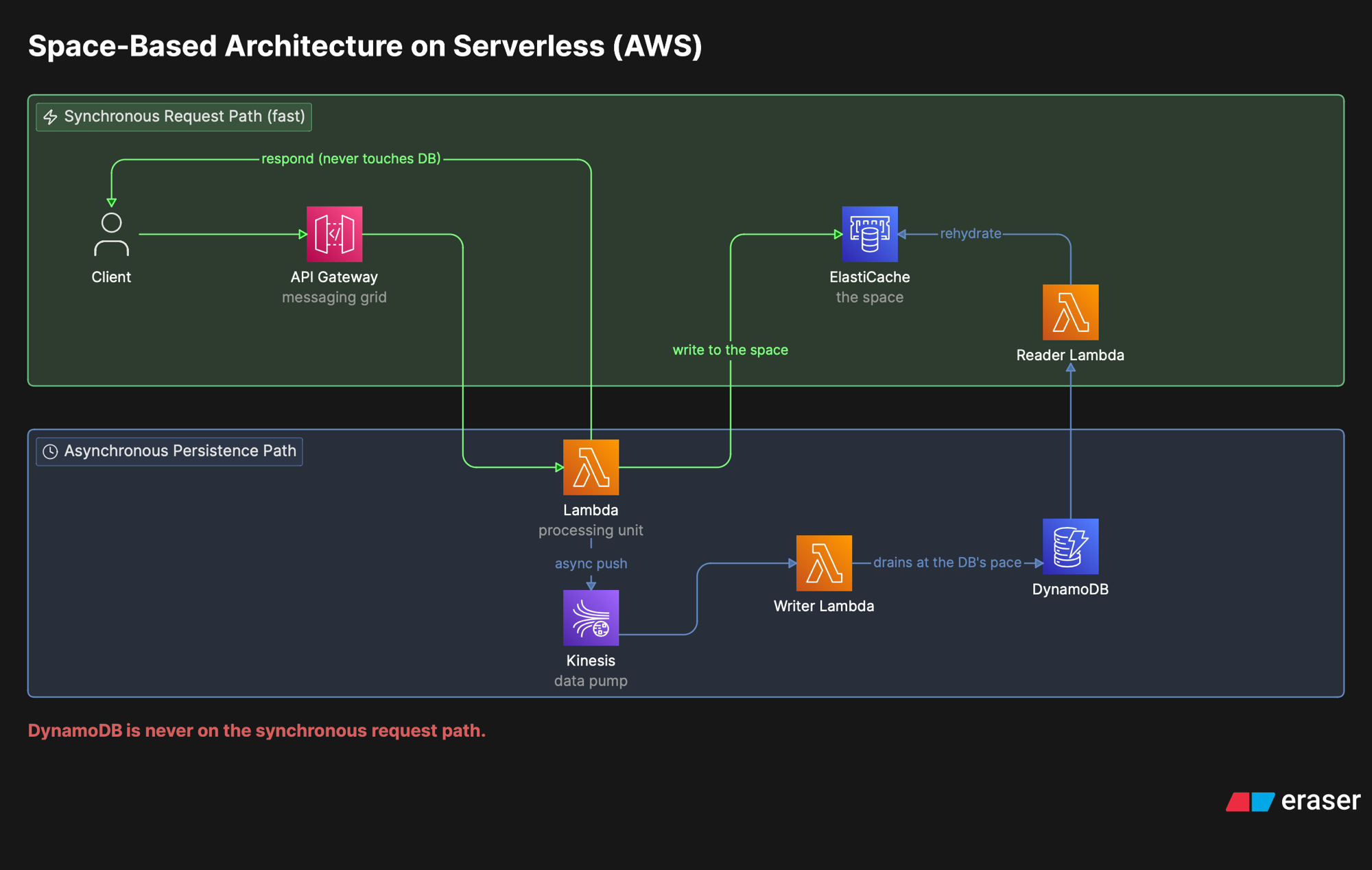
O mesmo padrão traduzido para serverless na AWS: API Gateway como messaging grid, Lambdas como processing units, ElastiCache como o espaço, Kinesis como data pump, e writer Lambdas drenando para o DynamoDB no ritmo do banco.
O coração da implementação está no caminho de escrita. A Lambda que atende a requisição não toca o banco. Ela escreve no espaço, empurra o evento para o data pump e responde:
def handler(event, context):
order = parse(event)
# Escreve no espaço (in-memory). Resposta em sub-milissegundo.
redis.hset(f"inventory:{order.sku}", mapping=order.to_cache())
# Empurra o fato para o data pump. Não espera o banco.
kinesis.put_record(
StreamName="orders-pump",
Data=order.to_event(),
PartitionKey=order.sku,
)
return ok(order) # cliente atendido sem nunca tocar o DynamoDB
A persistência fica numa Lambda separada, consumidora do stream, que escreve no DynamoDB em lote. Ela processa no ritmo do banco, e se um pico de dez segundos gera um milhão de eventos, eles ficam bufferizados no Kinesis e são drenados nos minutos seguintes sem que nenhum cliente tenha percebido:
def writer_handler(event, context):
# Consome o data pump no ritmo do banco, em lotes.
with dynamodb.batch_writer(table="Orders") as batch:
for record in event["Records"]:
batch.put_item(Item=decode(record))
A consequência dessa separação é o que define a arquitetura: o pico de escrita bate no Redis e no buffer do Kinesis, que aguentam volume com folga, e nunca no DynamoDB de forma síncrona. O banco deixa de ser o gargalo porque deixou de estar no caminho da requisição.
Falei do caminho de escrita, mas no pico o volume maior costuma ser de leitura: milhões de pessoas checando se ainda tem ingresso. Aí o espaço trabalha a seu favor de graça, a leitura é servida direto do Redis, que é exatamente o que ele faz bem, e disponibilidade nunca toca o banco no caminho feliz. O cuidado é com cache miss em massa, que cai no problema de reidratação que vou tocar nas desvantagens.
Um detalhe que não é opcional: colisão de dados. No exemplo do ingresso, você precisa garantir que cinquenta mil unidades não virem cinquenta mil e uma. Na arquitetura clássica, o data grid lidava com isso entre os processing units. Em serverless, isso se centraliza no Redis, e você resolve com as primitivas dele, operações atômicas, scripts Lua, ou optimistic locking com WATCH. O decremento de estoque tem que ser atômico no espaço, não no banco. Se você esquecer disso, a arquitetura funciona lindamente até o dia do pico real, e aí oversell vira problema jurídico.
E tem uma armadilha de simetria aqui. Você acabou de tirar o hot key do DynamoDB e jogou ele no Redis, que é single-threaded por shard. Um SKU que viralizou serializa todos os decrementos num núcleo só, e cluster mode não fatia uma única chave entre nós, ela mora num slot só. Um Redis primary aguenta muito mais que as mil escritas por segundo do DynamoDB, então a dor é menor, mas no caso mais extremo a solução é a mesma ideia do write coalescing, só que do lado da leitura: shardar o contador, quebrar inventory:{sku} em N sub-chaves, decrementar uma aleatória e somar na hora de ler.
O que não está no diagrama: idempotência, conexões e observabilidade
Tem três coisas que o diagrama bonito esconde e que decidem se isso funciona no dia do pico. As três derrubam projeto.
A primeira é idempotência. Tanto SQS quanto Kinesis entregam pelo menos uma vez, então o seu writer vai reprocessar mensagem, é questão de quando, não de se. O batch.put_item ingênuo do exemplo replica escrita. O que te salva aqui é que o DynamoDB nessa arquitetura é projeção, não fonte da verdade, o Redis já tem a contagem autoritativa. Então um PutItem com chave determinística, id do pedido ou id do evento, é naturalmente idempotente: reaplicar dá no mesmo. O que você não pode fazer é update aditivo no banco, somar ou incrementar, sem chave de deduplicação, porque aí cada redelivery soma de novo e a projeção mente. E no Kinesis, configure on-failure destination e bisect on error, senão um batch envenenado trava a shard inteira e o pump para sem ninguém ver.
A segunda é conexão, e é a falha mais específica de fazer isso em serverless. ElastiCache e MemoryDB vivem dentro de uma VPC, então a Lambda precisa estar na VPC para alcançar o espaço, e o cliente Redis tem que ser instanciado fora do handler, em escopo de módulo, para ser reaproveitado entre invocações quentes. O problema de verdade aparece no pico: Lambda escala para centenas ou milhares de execution environments simultâneos, e cada um abre conexão com o Redis. Isso é um connection storm em cima de um endpoint que tem limite de clientes, e é exatamente o tipo de falha que não acontece na arquitetura clássica, onde o grid vive dentro do processo. A boa notícia é que o terror antigo de cold start de Lambda em VPC acabou: desde as Hyperplane ENIs a penalidade é sub-segundo, não os dez segundos de antigamente.
A terceira é observabilidade. Pipeline assíncrono não tem trace síncrono ligando a requisição do cliente à escrita final no banco. A requisição entra na API, passa pelo Redis, é desacoplada no buffer e é persistida segundos depois por outra Lambda. Quando algo trava no pico, você não tem um stack trace, tem peças soltas. Instrumente com X-Ray propagando contexto manualmente pelo buffer e, mais importante, alarme no iterator age do Kinesis ou no age of oldest message do SQS. Esse é o número que te avisa que a persistência está ficando para trás antes do cliente perceber.
As vantagens de fazer isso em serverless
A maior vantagem é que a parte mais difícil da space-based architecture some. O deployment manager, a orquestração de subir e descer processing units conforme a carga, é exatamente o que Lambda e os serviços gerenciados entregam de graça. Você não opera cluster de Hazelcast, Ignite ou GemFire, não dimensiona fleet, não escreve lógica de elasticidade. Na arquitetura tradicional, isso é meses de engenharia e uma fonte permanente de incidentes. Aqui é configuração.
O custo vem junto. A versão clássica é cara porque você mantém um grid de máquinas pesadas de memória ligadas o ano inteiro para o pico que acontece em dois ou três dias. Serverless inverte isso: você paga as Lambdas por uso, escala para perto de zero entre os picos, e só o Redis fica sempre ligado. Para um negócio cujo evento crítico é sazonal, isso é dinheiro de verdade no fim do mês.
E tem o lado operacional, que pra mim é o que mais pesa. Com o banco fora do caminho crítico, o componente mais difícil de escalar do seu sistema deixa de ser o que decide sua disponibilidade no pior momento. Te garanto que dormir tranquilo na véspera de uma venda de ingresso de estádio inteiro vale mais do que qualquer benchmark de latência.
As desvantagens, que são reais
A primeira desvantagem é a latência, o custo que prometi detalhar lá atrás. O cache in-process replicado, a feature de assinatura da arquitetura, não existe. Todo acesso ao espaço é um hop de rede até o Redis. Você sai do acesso in-process em nanossegundos para um round-trip de rede que, com ElastiCache Serverless, fica na casa do sub-milissegundo. Rápido, mais que suficiente para a esmagadora maioria dos casos, mas não é a mesma coisa, e se o seu caso de uso precisa do acesso in-process de verdade, serverless não é o lugar.
A segunda é cruel pela ironia: cold start. Você está desenhando para o pico, e o pico é exatamente quando o Lambda precisa subir centenas de execuções novas, cada uma pagando a latência de inicialização. Provisioned concurrency resolve, mas custa dinheiro e mina parte do benefício de escalar para zero. Agora, na maioria dos casos que justificam essa arquitetura o pico é agendado, a venda abre às dez. Isso muda o jogo: você pré-aquece. Sobe provisioned concurrency programada e pré-carrega o estoque no Redis antes da hora, em vez de descobrir o cold start no primeiro segundo da venda. E tome cuidado com o efeito inverso na reidratação: se o espaço cai no meio do pico, todas as Lambdas dão cache miss ao mesmo tempo e estouram o DynamoDB para repopular, recriando exatamente a sobrecarga que a arquitetura existe para evitar. A proteção é single-flight, uma Lambda reidrata enquanto as outras esperam, não um stampede.
A terceira é a consistência, e com ela vem o risco de perda de dado. A persistência é assíncrona por design, então o banco está sempre atrás do espaço. Qualquer consumidor que leia direto do DynamoDB esperando o último dado escrito vai ler dado velho. Eventual consistency deixa de ser detalhe e vira premissa de projeto: todo componente downstream precisa ser desenhado sabendo que o banco lag atrás da realidade. E se você usa o espaço como cache, que é o uso típico no modo serverless, quando ele morre antes do pump drenar você perde a janela de escritas que ainda não foi persistida, tipicamente alguns segundos no pior caso. O que você não pode fazer é tratar um cache como fonte da verdade achando que ele é durável. O Jepsen já demonstrou de forma cristalina que in-memory grids como Hazelcast, sob partição de rede, perdem e duplicam dados de formas que você não quer descobrir em produção. Se o dado é financeiro e não pode se perder, você precisa de durabilidade de verdade no próprio espaço: MemoryDB sempre foi durável, e o ElastiCache para Valkey ganhou modo durável recentemente, mas em nós, não no serverless. O preço dos dois é o mesmo, escrita mais lenta e um componente sempre ligado.
A quarta é que o espaço não é serverless de verdade. Mesmo com ElastiCache serverless, você tem um componente sempre ligado, com limite de memória e custo associado, no meio de uma arquitetura que você escolheu por causa da elasticidade. Não existe, hoje, um in-memory grid genuinamente serverless com a mesma semântica do grid clássico. É uma costura, e costuras têm custo.
E a quinta, a que mais importa: complexidade. Richards e Ford dão a essa arquitetura a nota mais baixa do livro em simplicidade, e serverless não conserta isso. Você agora tem API Gateway, Lambdas de processamento, Redis, Kinesis, Lambdas de escrita, DynamoDB e lógica de reidratação, tudo para um padrão que só se justifica sob um perfil de carga muito específico. Testar isso é outro pesadelo: a arquitetura existe para o pico, e reproduzir o pico em ambiente de teste é caro e difícil. Você descobre se acertou no dia em que não pode errar.
A alternativa que muita gente ignora: atacar o pico na admissão
Antes de falar de quando não usar, preciso colocar na mesa a alternativa que muita gente esquece. Space-based architecture ataca o pico na absorção: deixa todo mundo entrar e aguenta o tranco em memória. Existe outra escola que ataca o pico na admissão: não deixa todo mundo entrar de uma vez. É o virtual waiting room, a fila de espera que serviços como Cloudflare Waiting Room e Queue-it implementam.
A ideia é direta. Em vez de dimensionar o sistema para dois milhões de pessoas simultâneas, você admite as pessoas num ritmo que o sistema aguenta, e o resto espera numa fila justa. E, por mais sem graça que pareça, é isso que a maioria das grandes plataformas de venda de ingresso realmente faz. É dramaticamente mais simples que montar um in-memory data grid, não tem risco de perda de dado no core porque é controle de admissão e não armazenamento, e na maioria dos casos é um produto gerenciado que você liga e configura.
A diferença de aplicabilidade é o que importa: waiting room funciona quando o pico é gente, e dá pra fazer a gente esperar. Quando o pico é máquina, telemetria de IoT, lances de real-time bidding, eventos que não dá pra colocar numa fila de espera porque ninguém está olhando, aí a absorção em memória volta a ser a resposta certa. Para venda de ingresso, na prática, recomendo muito avaliar o waiting room antes de qualquer coisa mais complexa.
Quando não usar, que é quase sempre
Vou ser categórico, porque é onde mais vejo gente errar: a esmagadora maioria dos sistemas nunca vai precisar disso, e construir mesmo assim é pagar a conta mais cara do catálogo por um problema que você não tem. Se a sua carga é previsível ou moderada, DynamoDB on-demand com um cache-aside comum já escala lindamente e é dez vezes mais simples. Você não precisa de data pump, não precisa reidratar grid, não precisa lidar com colisão centralizada no Redis. Você precisa de um banco que escala, e a AWS te dá isso pronto.
Mas tem uma exceção que muda a régua, e é exatamente onde o princípio deixa de ser luxo e vira necessidade: o hot key. O DynamoDB tem um limite por partição de mil unidades de escrita por segundo, e esse limite é hard, o modo on-demand não levanta ele. Não importa a capacidade da tabela. Se o seu pico concentra num único item, o estoque de um show específico, um SKU que viralizou, você throttla naquela partição enquanto o resto da tabela está ociosa. É justamente aqui que “é só ligar o on-demand” falha. E a solução, absorver o decremento no Redis com operação atômica e fazer write coalescing para o banco, é o princípio da space-based architecture reaparecendo, mesmo que ninguém o chame pelo nome. Então a pergunta certa não é “minha carga é alta?”. É “meu pico concentra num único key?”. Se concentra, você vai herdar o princípio querendo ou não. Se está bem distribuído, o banco gerenciado escala e você não precisa de nada disso.
Isso conversa direto com algo que já defendi sobre pensar por primeiros princípios em vez de copiar padrões: o erro não é técnico, é de raciocínio. Adotar a arquitetura mais complexa do catálogo porque ela é elegante, ou porque uma big tech usa, sem ter o perfil de carga que a justifica, é o mesmo que fazer mise en place para mil pratos numa noite em que vão entrar trinta. Você preparou o restaurante inteiro para um rush que não vem, e paga o custo da prep todo santo dia. Decompõe o problema primeiro. Pergunta se você realmente tem um pico de escrita imprevisível concentrado, que derruba o banco, ou se você só tem um cache mal configurado. Te garanto que, em nove de cada dez casos, é a segunda.
Space-based architecture faz sentido quando você comprovou, com carga real ou projeção honesta, que o banco é o gargalo e que o pico, concentrado num único ponto, é a forma do problema. Ingresso de show, leilão, aposta ao vivo, flash sale de escala absurda. Fora disso, a complexidade que ela adiciona custa mais do que o problema que ela resolve.
Fechando
Space-based architecture resolve um problema específico e real: o pico de escrita imprevisível que nenhum auto-scaling de aplicação salva, porque o gargalo é o banco. Ela faz isso tirando o banco do caminho crítico, atendendo a transação em memória e persistindo de forma assíncrona. Em serverless na AWS, você não implementa a versão literal, com seus processing units de vida longa e grid replicado in-process; você herda o princípio e deixa a plataforma cuidar da elasticidade, com ElastiCache como espaço, Lambda como processing unit, Kinesis como data pump e DynamoDB como destino assíncrono. Ganha elasticidade e custo, perde o acesso in-process e herda eventual consistency e complexidade.
O próximo passo concreto, antes de desenhar qualquer coisa disso, é medir. Faz um load test no seu design atual e descobre onde o banco realmente quebra, e sob que forma de carga. E teste a coisa certa: não espalhe a carga por mil chaves, concentre num único key, que é onde quebra de verdade, e suba a concorrência de forma abrupta para provocar o connection storm. Olha os throttles do DynamoDB, as conexões e a CPU do Redis, o iterator age do buffer. Carga espalhada e suave passa no teste e falha na venda. Se o banco aguenta o seu pico real, você não precisa de space-based architecture, e saber disso já te poupou meses. Se ele quebra, e quebra do jeito específico que descrevi, aí sim vale montar um POC pequeno com API Gateway, Lambda, ElastiCache serverless, Kinesis e DynamoDB, e medir de novo. A arquitetura certa nunca vem do diagrama mais bonito. Vem do número que você mediu.