
The most uncomfortable question an architect can get after a serverless migration is simple: why does every deploy now require coordination between four teams? The technical answer is hard. The organizational one is worse, because it reveals that the architecture promised team autonomy and delivered the opposite.
This isn’t serverless’s fault. It’s missing domain design. And the design that solves it has been around for over 20 years: Domain-Driven Design.
The Lambda zoo
I’ve seen this scenario more times than I’d like. A team adopts serverless, starts creating functions, APIs, tables. Everything works, deploys are fast, the AWS bill is under control. Six months later there are 300 Lambdas, 15 APIs in API Gateway, events flying everywhere through EventBridge, and nobody can answer a basic question: “where does this service end?”
What happened is classic: they scaled the infrastructure without scaling the design. Serverless makes resource creation easier than any other model. So easy that, without discipline, you build a distributed monolith without realizing it. Each Lambda is small and independent on paper, but the whole thing is a tangled mess that no architecture diagram can save.
And the most dangerous coupling isn’t the obvious one. When a Lambda from the payment domain hits the orders domain’s DynamoDB table directly, you have data coupling. It doesn’t matter that they’re separate functions, independent deploys, different stacks. The coupling lives in the persistence layer, and that’s the hardest kind to untangle.
What DDD has to do with serverless
Domain-Driven Design was created by Eric Evans in 2003 for object-oriented software. The concepts are over two decades old and were designed for a world very different from serverless. But the essence of DDD, organizing software around the business domain rather than the technology, is what’s missing in most serverless projects that grow beyond trivial.
Instead of organizing your architecture by resource type (Lambdas here, databases there, queues over there), you organize by business domain. Payment is a domain. Customer is another. Order is another. Each domain has its boundaries, its data, its rules. And those boundaries are what stop growth from turning into mess.
In my experience, what separates a serverless project that works at scale from one that becomes an operational nightmare is clear boundaries between domains. It doesn’t matter if you use SAM or CDK, what runtime your Lambda runs, or how much of your IaC is automated. If you don’t have a domain model that organizes the system in a way the business recognizes, the mess is just a matter of time.
From domains to domain services
Let’s go to the practical mapping. Take an e-commerce domain. The overall domain is “e-commerce”. Within it, you have sub-domains: Order, Payment, Customer, Delivery, Inventory. In DDD, each sub-domain encapsulates a business capability with its own rules and data.
In serverless, each sub-domain becomes a domain service: a complete and autonomous service. On AWS, this typically materializes as an API Gateway as the entry point, a set of Lambdas implementing the logic, one or more dedicated databases (DynamoDB in most cases), and events published via EventBridge.
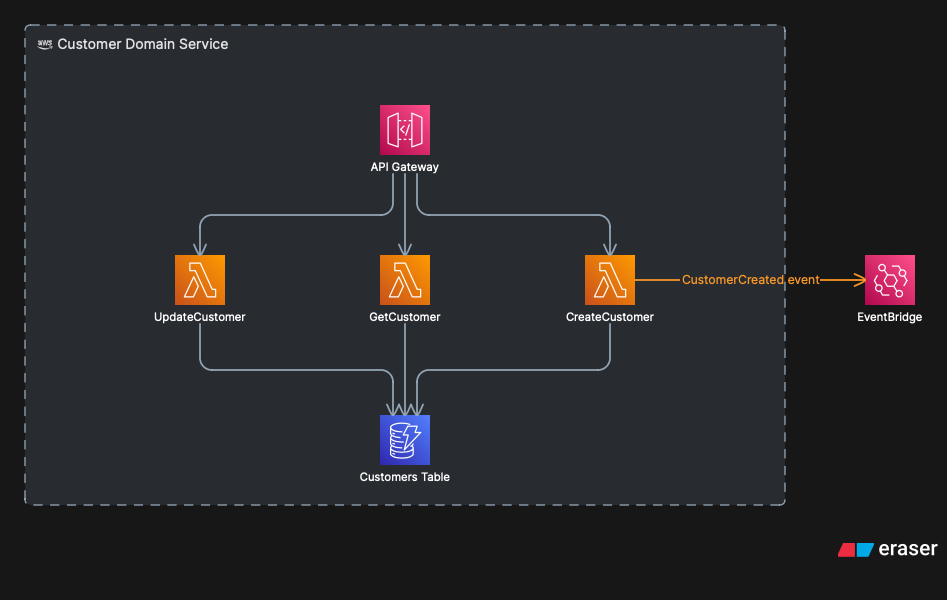
Anatomy of a serverless domain service: API Gateway as the entry point, Lambdas and DynamoDB inside the bounded context, and a CustomerCreated event published externally through EventBridge.
Inside each domain service live one or more microservices. In DDD vocabulary, each microservice corresponds to an aggregate: a consistency unit that encapsulates a root entity and the business logic around it. The Customer domain service, for example, can have an aggregate for “Registration” and another for “Loyalty Program”. Each with its own Lambdas and tables, but within the same domain.
The fundamental rule: these internal aggregates can communicate directly with each other through SQS, direct invocation, whatever fits the case. But communication with other domain services goes through the public API or domain events. Direct access to another domain’s database is forbidden. No exceptions.
In practice, each entity (like “Customer”) has an immutable identifier and lives within an aggregate. Value objects (like “Customer Address”) don’t have their own identity and exist as attributes linked to the entity. In DynamoDB, this can be modeled with adjacent list patterns, where the value object is a child of the root entity, referenced by partition key. Looks like a modeling detail, but the distinction matters: it defines what can and cannot exist outside the context of the main entity.
Bounded context: the boundary that makes serverless actually work
If there’s a DDD concept I consider the most important for serverless, it’s bounded context.
A bounded context is the boundary around a domain service. Everything inside that boundary uses the same data model, the same language, the same rules. What’s outside doesn’t access directly: it goes through the API or consumes events. Real encapsulation, at the architecture level.
In AWS serverless, this gets a very concrete translation. Each bounded context can be a separate AWS account inside an Organization (or at minimum an isolated stack), with its own API Gateway, its own databases, its own IAM policies. The team responsible for the domain controls everything inside. What’s outside is a public contract, documented via OpenAPI, versioned, and stable. Other teams see the integration interfaces and that’s it. Cognitive load reduced.
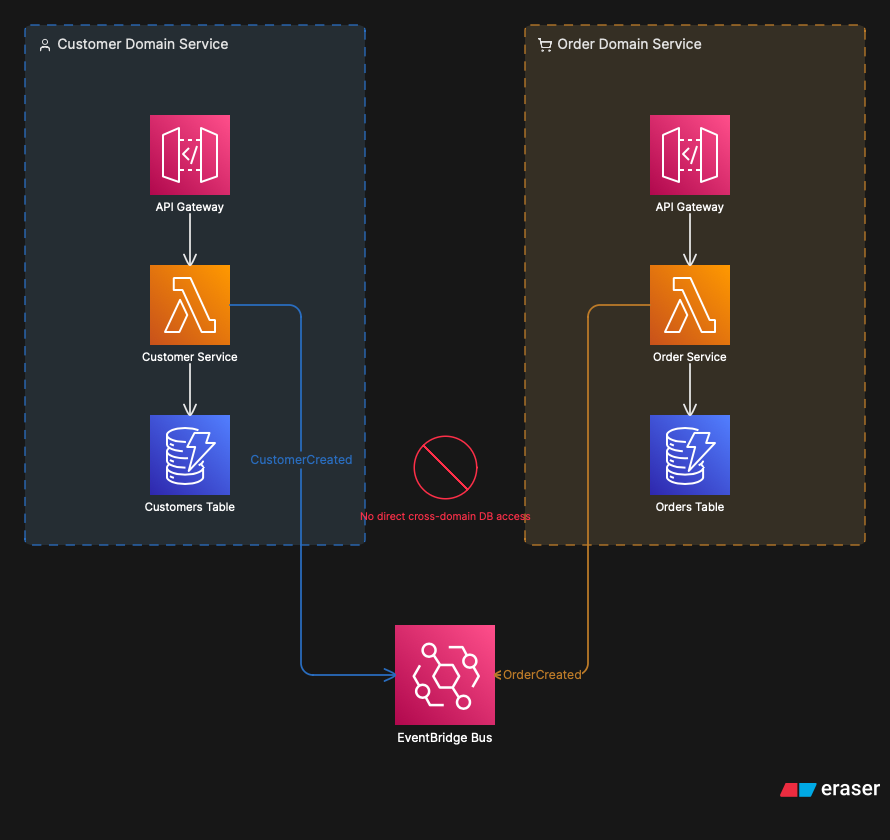
Two isolated bounded contexts communicating exclusively through EventBridge. Direct access to a neighboring domain’s database is forbidden by design, not by policy.
Speaking from experience, when I saw teams apply bounded contexts with discipline, the most visible gain wasn’t technical. It was organizational. Teams stopped stepping on each other’s toes, deploys no longer required coordination between squads, and incidents stayed contained inside the domain that failed instead of cascading across the whole system. That’s the independence every microservices project promises but rarely delivers without clear bounded contexts.
The absence of bounded contexts is, in my experience, the number one reason serverless projects turn into distributed monoliths. The dependency that kills isn’t the code one, it’s the data one. Any schema change in the neighboring domain will silently break your service, and you’ll only find out in production.
Domain events and EventBridge
If bounded contexts define the boundaries, domain events are the communication mechanism between them. And in most cases, this communication needs to be asynchronous.
A domain event is a fact that happened in the domain. “Payment confirmed”, “Delivery cancelled”, that kind of thing. The domain service that generated the fact publishes the event. Whoever needs to react, consumes. The publisher doesn’t know and doesn’t need to know who’s on the other side.
On AWS, EventBridge plays this role. Each domain service publishes its events to a bus (shared or dedicated, depending on your organization), and other domain services configure rules to consume what interests them. The Payment service publishes “PaymentConfirmed” and moves on. If Order, Notification, and Analytics want to react to it, that’s their problem. Payment doesn’t change a single line of code.
This solves a real coordination problem between teams. Without domain events, the easiest path is synchronous calls between services. And synchronous calls create fragile dependency chains where the failure of one service cascades to everyone depending on it. With domain events, each team controls its domain end to end. When you need to add a new consumer, you just create a new EventBridge rule. No deploy on the publishing service.
A point about the experience layer: not every event needs to be a domain event. In a BFF (backend for frontend), an event like “customer logged in” or “customer sentiment is negative” can make sense as an application event without being a domain event. The distinction matters to avoid polluting the domain bus with events that only matter to the presentation layer.
Types of domain: where to invest and where to be pragmatic
DDD classifies sub-domains into three types. This classification has direct impact on how much design effort you put into each domain service, and it’s one of the most useful things from DDD in practice.
Core is what differentiates your business from competitors. If you run an e-commerce, the recommendation engine, the optimized checkout, the predictive inventory management. Evans estimates that the core domain delivers about 20% of the total system value with about 5% of the code and consumes about 80% of the effort. This is where you put the best engineers, the most rigorous design, the most complete tests. If the core domain isn’t well modeled with bounded contexts, aggregates, and clear domain events, the rest doesn’t matter much.
Supporting holds up the core without being a differentiator. Customer registration, address management, purchase history. Needs to work well, but isn’t what wins the market. Serverless shines here because of simplicity: API Gateway, Lambda, DynamoDB, done. These domains are candidates to be developed by less specialized teams or outsourced.
Generic is commoditized functionality. Email sending, invoice generation, authentication. The rule is direct: buy before building. SES for email, Cognito for auth, a SaaS for invoicing. Don’t waste engineering building what already exists as a commodity, your competitive edge isn’t there.
This classification helps calibrate investment. Not every domain service needs a dedicated AWS account, formal bounded context with EventBridge, and versioned API. The “transactional email sending” service can be one Lambda and SES, no aggregate, no elaborate modeling. The core domain, on the other hand, deserves all the rigor, because that’s where the competitive advantage comes from.
Anti-corruption layers: protecting your domains from legacy systems
A DDD concept that becomes especially relevant in migration scenarios is the anti-corruption layer. The idea is simple: when you need to integrate a new domain service with a legacy system, you put an intermediate layer between them that translates the models. Legacy speaks its language, the domain service speaks its own, and the anti-corruption layer translates.
In AWS serverless, this implements as an integration service, usually in the experience layer. A Lambda (or a Step Function, depending on complexity) that receives the legacy system’s DTO, transforms it into the format the domain service expects, and forwards it. The reverse path works the same way.
With this in place, your new domain service doesn’t inherit the bad decisions from the old system. And when the legacy is eventually retired, you remove the translation layer without touching the domain.
Ubiquitous language: the contract that isn’t technical
One last concept worth mentioning: ubiquitous language. In DDD, it’s the practice of building a common language between engineering, product, and business. Everyone uses the same terms for the same things. “Order” means the same thing to the dev, to the PO, and to the stakeholder.
Looks trivial, but in practice the lack of this generates communication bugs that turn into software bugs. If the engineering team calls “order” what the business calls “request”, and the database calls “requisition”, eventually someone is going to implement the wrong rule because they understood the wrong concept. In organizations operating across multiple regions, where domain services need to be internationalized and reused, having a globally defined ubiquitous language isn’t a luxury. It’s a necessity.
In serverless, this reflects in the names of EventBridge events, in API paths, in table names, in stack names themselves. If the domain is called “Customer”, the event is “CustomerCreated”, the table is “Customers”, the path is “/customers”. Consistency between code and business.
When DDD is over-engineering
Not every serverless project needs DDD. If you have a small team, a simple domain, and 30 Lambdas, creating formal bounded contexts with structured domain events and separate AWS accounts per domain will hurt more than help.
DDD makes sense when multiple teams work on the same system and the domain is complex enough to justify decomposition. In practice, this shows up when the organization passes hundreds of functions and needs real deploy independence between teams.
If you’re a team of 3 building an MVP, focus on shipping. DDD comes later, when complexity justifies it. The classic mistake is adopting it too early or too late. Too early is bureaucracy that locks the team without delivering benefit. Too late is trying to reorganize hundreds of coupled functions already in production serving real customers. I guarantee the second one hurts much more than the first.
Back to the uncomfortable question
DDD isn’t new. Neither is serverless. But putting them together is what allows you to scale serverless at enterprise without losing control. Evans’s concepts, over 20 years old and designed for a different world, fit the serverless model in a way I didn’t expect when I started applying them. Sub-domains become domain services with their own APIs, bounded contexts take concrete shape as isolated AWS accounts, aggregates translate into encapsulated microservices, and domain events flow through EventBridge.
If your serverless project is becoming hard to understand and hard to split between teams, it’s a design problem, not a technology problem. Start by mapping the business sub-domains together with product, define clear bounded contexts with versioned APIs, and make sure all communication between domains goes through events or public APIs. Never through direct access to another domain’s data.
Next time someone asks why every deploy needs coordination between four teams, the answer won’t be technical. It’ll be architectural. And the biggest mistake in serverless architecture has never been about choosing Lambda over containers. It’s been about thinking serverless exempts you from doing domain design.