
It’s ten in the morning, the show just went on sale, and two million people hit refresh at the same time to fight over fifty thousand tickets. Your API scales. Lambda scales. API Gateway scales. And the database melts. Not from total volume, DynamoDB on-demand would handle that. It melts because everyone hits the same item, the inventory for that one show, and a single hot partition throttles while the rest of the table sits idle. The bottleneck was never the load. It was the hot key.
I’ve seen this movie a few times in high-concurrency systems, and the team’s typical reaction is the wrong one: throw in more read replicas, a bigger connection pool, a cache in front. It helps at the edges, but it doesn’t fix the structural problem. When the spike is write-heavy, unpredictable, and concentrated on a single point, the answer isn’t to scale the database. It’s to take the database out of the critical path. That’s exactly the problem space-based architecture was designed to solve, and that’s what this article is about, applied to serverless on AWS. Because you’re going to end up implementing its principle one way or another. The only choice is whether it happens in the design or in the middle of the incident.
What space-based architecture is
The name comes from the tuple space, an idea from the 1980s coordination language Linda, later popularized by JavaSpaces: a shared, distributed memory where processes read and write data without talking directly to each other. Mark Richards and Neal Ford catalog this architecture in Fundamentals of Software Architecture, and it’s, no exaggeration, the most complex one in the book. It’s not an architecture you adopt for elegance. It’s one you adopt because you’ve exhausted the other options.
The central premise is a single one: the database is the scale limit of most systems. You can scale the web tier and the application tier almost indefinitely, but at some point everyone converges on the same database, and that’s where the queue forms. Space-based architecture solves this by removing the database from the transactional flow. Instead of reading and writing to the database synchronously, the application works against a replicated in-memory data grid, and persistence happens asynchronously, in the background, without blocking any request.
Picture a restaurant kitchen at the peak of Friday night service. If every server had to run to the supplier for an ingredient on every dish, the kitchen would collapse on the first rush. That’s not how it works. Before service, everything is prepped in the mise en place: ingredients are within reach, in memory, ready. During the rush, nobody touches the supplier. You cook at full speed from the prep station, and restocking happens afterward, at the pace of whoever’s restocking, without stalling a single ticket. The supplier is the database. The mise en place is the in-memory data grid. And whoever restocks the pantry between tickets is what the architecture calls the data pump.
The components are well defined. The processing unit is the unit of scale: it holds the business logic and an in-memory copy of the data it operates on. You scale by spinning up more processing units, and each one carries its own grid. Above them sits the virtualized middleware, which coordinates everything, and it has four parts. The messaging grid routes requests to the available processing units and manages session. The data grid is the heart of the architecture: it replicates data across the processing units, so that when one updates something, the others see that change. The processing grid is optional and orchestrates requests that involve multiple types of processing unit. And the deployment manager spins processing units up and down dynamically with load.
Closing the loop, the data pumps send updates asynchronously and with guaranteed delivery to be persisted. The data writers consume the pump and write to the database at whatever pace the database can take. And the data readers do the reverse: they read from the database to populate the in-memory grid when the system boots up or when all instances of a processing unit type go down and the memory is lost.
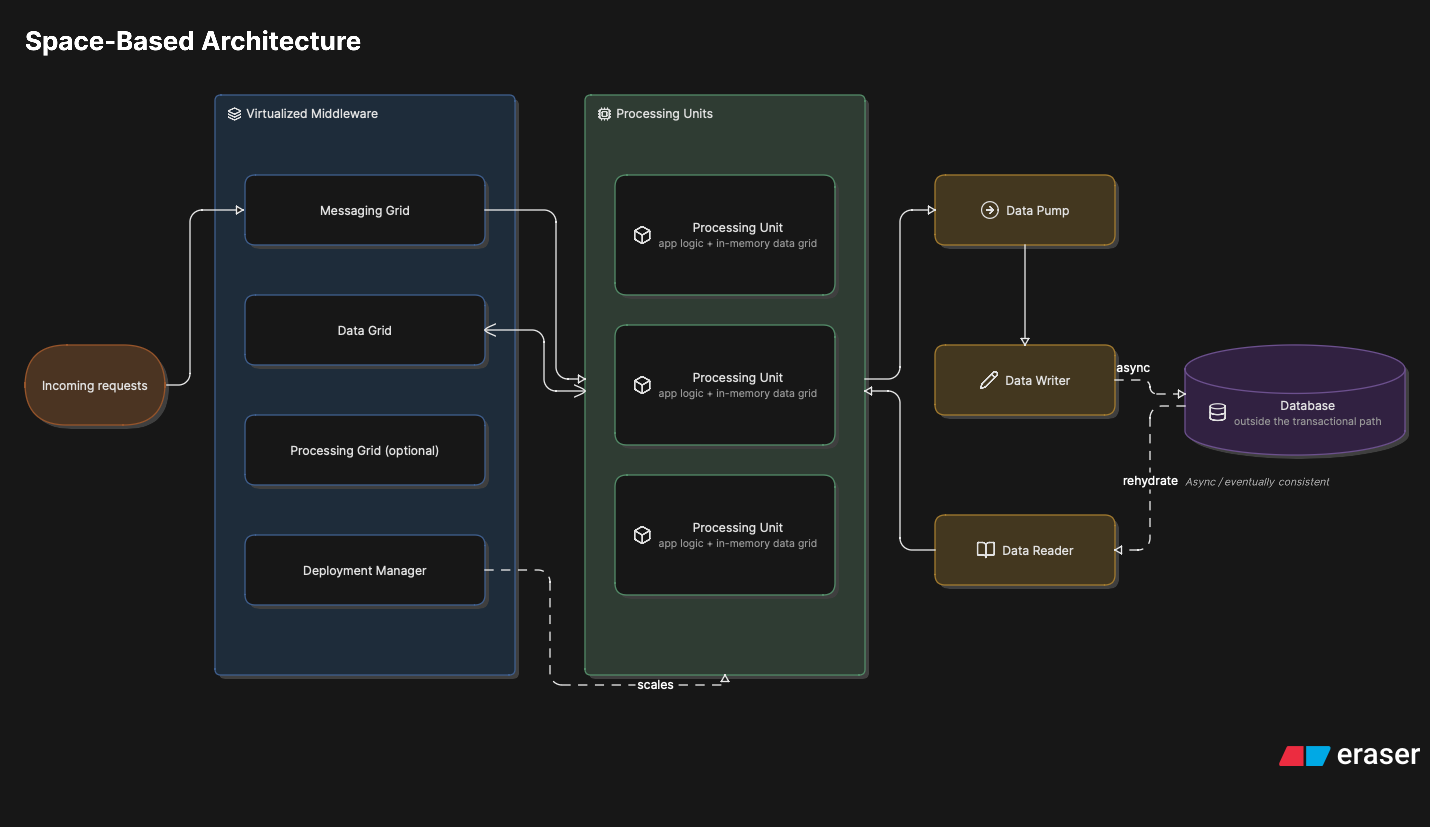
Anatomy of space-based architecture: processing units with an in-memory data grid, the virtualized middleware coordinating, and the database outside the transactional path, fed asynchronously by the data pumps.
It’s worth understanding one decision that defines how the architecture behaves: replicated cache versus distributed cache. In a replicated cache, each processing unit holds a full copy of the data in memory, in its own process. It’s absurdly fast, nanosecond access, and resilient, because it doesn’t depend on a central server. The price is size, you’re limited by each instance’s memory, and data collision, when two processing units update the same data at almost the same time. In a distributed cache, the data lives on a central server and the processing units reach it over the network. It fits far more data, but you pay in latency and in a new point of dependency. Hold on to this distinction, because it’s the pivot of everything once we take this to serverless.
Why this matters and when it makes sense
Space-based architecture isn’t general purpose. It exists for a very specific load profile: high, variable, unpredictable concurrency, usually write-heavy. Ticket sales, Black Friday flash sales, online auctions, live betting, real-time game leaderboards, any viral event where volume jumps from hundreds of requests per minute to hundreds of thousands per second in a matter of moments.
What makes these cases special isn’t the average volume, it’s the shape of the spike. A system with high but predictable load you just size and move on. The problem is the spike that shows up without warning and lasts seconds. Provisioning the database for the peak is expensive and wasted the rest of the year; not provisioning it means accepting that the system goes down at exactly the moment of greatest value to the business. Space-based architecture breaks that trade-off: it moves the transaction into memory, absorbs the spike where it hurts, and lets persistence drain at whatever pace it can.
Personally speaking, this is the point that separates who understands the architecture from who just memorized the diagram: the goal was never general performance, it was absorbing extreme elasticity without the slowest point in the system, the database, setting the ceiling. If your system doesn’t have that load profile, you don’t have the problem it solves, and it becomes dead weight. I’ll come back to this at the end, because it’s where most teams get it wrong.
In practice, almost nobody runs a classic in-memory data grid, like GigaSpaces or Hazelcast, as the source of truth these days. What high-scale systems do is inherit the principle. Trip.com decrements inventory in Redis first and only then persists to MySQL asynchronously through a queue; it handles over a hundred thousand orders per minute and 45x spikes with the database out of the path. DraftKings, which has one of the most brutal spike profiles there is, the Super Bowl, keeps its financial ledger in Aurora MySQL, not in an in-memory grid: around a million operations per minute, with sharding by consistent hashing on the user id and read replicas under 15ms. The lesson is the same in both: the principle of space-based architecture survives, the literal implementation doesn’t.
The tension between space-based architecture and serverless
As strange as it sounds, space-based architecture and serverless are, in their canonical form, almost incompatible. And that needs to be clear before any pretty diagram.
The classic architecture depends on long-lived processing units that hold data in memory, in their own process, and replicate that state among themselves. Lambda is the opposite of that: stateless, ephemeral, no shared memory across invocations, free to die at any moment. That in-process replicated cache that gives space-based architecture its nanosecond access simply doesn’t exist in a model where the function has no guarantee of continuity whatsoever. You have nowhere to keep the grid.
So let me be direct: you don’t implement literal space-based architecture on Lambda, you inherit the principle. Taking the database out of the write path, serving the request against a fast in-memory layer, and persisting asynchronously by absorbing the spike in a buffer: that’s entirely doable in serverless. What changes is that the in-process replicated cache necessarily becomes an external distributed cache, with a network hop in the middle. That carries a latency cost I’ll detail further on. But in exchange, you get native elasticity for free, which is exactly the hardest and most expensive part to build in traditional space-based architecture.
How to build this in serverless on AWS
The mapping is straightforward, once you accept that the “space” leaves the process and becomes a managed service. Every component of the classic architecture has an equivalent:
| Classic component | AWS service | Note |
|---|---|---|
| Processing unit | Lambda | Business logic; reads and writes the space, never the database |
| Messaging grid | API Gateway | Routing; has a default RPS limit, raise the quota before the peak |
| Data grid (the space) | ElastiCache or MemoryDB | Redis-compatible; cache or durable |
| Processing grid (optional) | Step Functions | Only when a request orchestrates several PU types; most don’t need it |
| Data pump | SQS or Kinesis | Asynchronous buffer between space and database |
| Data writer | Lambda | Drains the pump and persists to the database in batches |
| Data reader | Lambda | Rehydrates the space from the database |
| Deployment manager | Native to the platform | Lambda elasticity + Redis scaling |
The space is the central decision, and it opens two very different topologies. For the cache role, ElastiCache in serverless mode handles most spike-absorption cases, and it does because what you need there is access throughput, not durability: the peak’s working set fits in memory and the database stays the source of truth. When the data in the space itself can’t be lost, the path is MemoryDB, durable in-memory with a multi-AZ transaction log, which can be the system of record itself. The deliberate choice between the two changes the whole design: either you use ElastiCache as a cache in front of DynamoDB, with a data pump and writer in between, cheaper and with a loss window; or you use MemoryDB as a durable space and eliminate the pump, the writer, and DynamoDB entirely, fewer moving parts, more expensive, single-digit ms writes, and no serverless mode. The first is the default for absorbing spikes; the second makes sense when the data is critical and you want fewer parts to operate.
The data pump carries a subtlety a lot of people get wrong. For pure spike absorption, SQS Standard is the simplest path and has practically unlimited throughput. Kinesis comes in when you need per-key ordering, replay, multiple consumers, or aggregation before writing, which is the case for write coalescing, merging a thousand decrements of the same SKU into a single write instead of a thousand. And there’s a detail that decides this for you: an inventory decrement is commutative, take one, take one, take one comes out the same in any order, and that’s exactly why SQS Standard without ordering is enough for the counter. Kinesis ordering only matters when the operation isn’t commutative, like a state transition or a last-write-wins field. If you’ve read what I wrote about domain events and EventBridge, the mechanics of decoupling through a queue will sound familiar; here it serves a different end, absorbing a spike, not isolating a domain.
The rest of the mapping is mechanical. The data writers are Lambdas consuming the buffer and persisting to DynamoDB in batches, at the database’s pace. The data readers repopulate Redis from DynamoDB on a cache miss or when the system boots from zero. And the deployment manager, that component you’d have to build and operate in the classic architecture to spin processing units up and down, here simply doesn’t exist as code you own: it’s Lambda’s native elasticity and Redis’s managed scaling. That’s the biggest win of the combination.
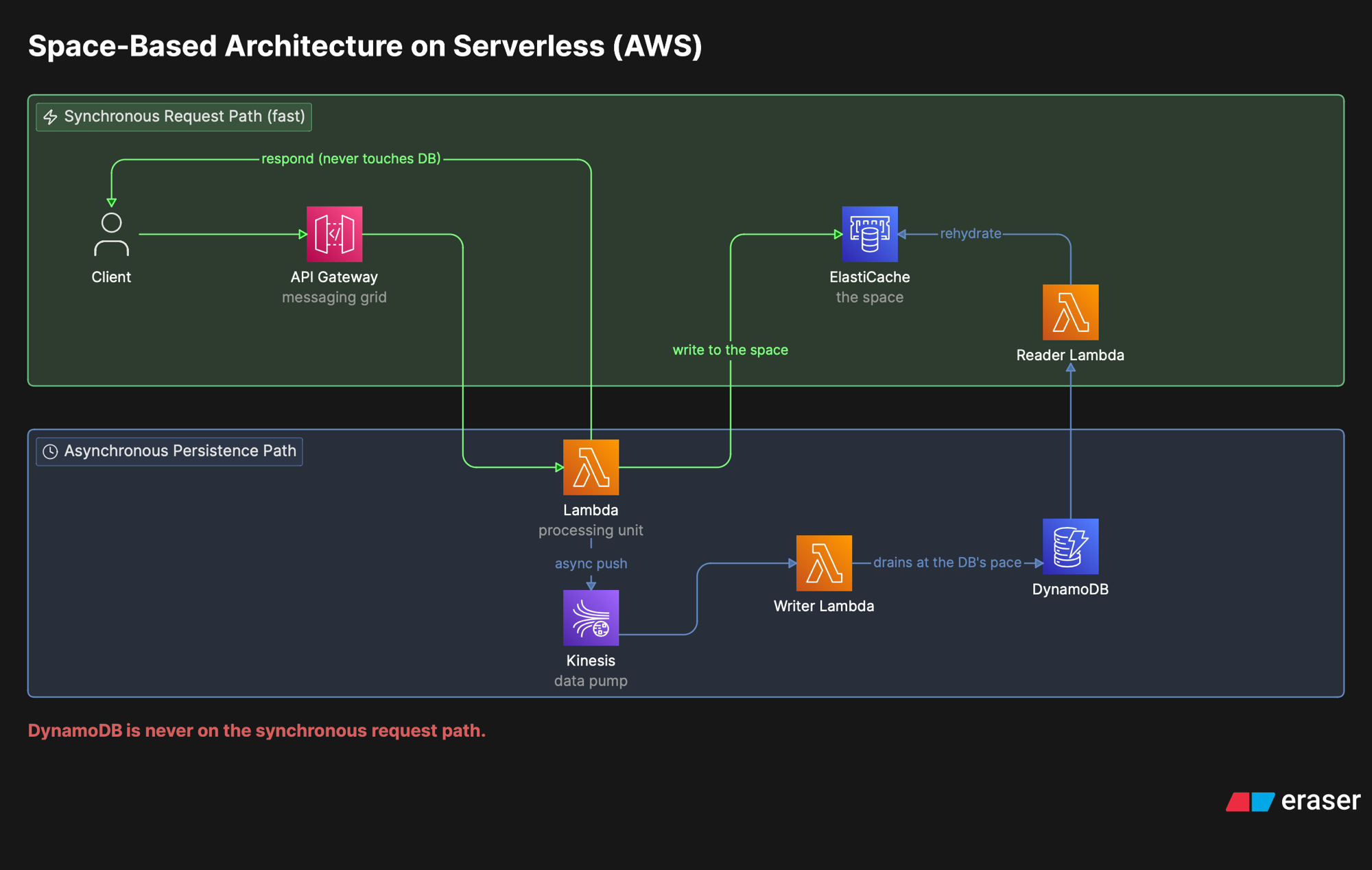
The same pattern translated to serverless on AWS: API Gateway as the messaging grid, Lambdas as processing units, ElastiCache as the space, Kinesis as the data pump, and writer Lambdas draining to DynamoDB at the database’s pace.
The heart of the implementation is in the write path. The Lambda that serves the request doesn’t touch the database. It writes to the space, pushes the event to the data pump, and responds:
def handler(event, context):
order = parse(event)
# Write to the space (in-memory). Sub-millisecond response.
redis.hset(f"inventory:{order.sku}", mapping=order.to_cache())
# Push the fact to the data pump. Don't wait on the database.
kinesis.put_record(
StreamName="orders-pump",
Data=order.to_event(),
PartitionKey=order.sku,
)
return ok(order) # client served without ever touching DynamoDB
Persistence lives in a separate Lambda, a consumer of the stream, that writes to DynamoDB in batches. It processes at the database’s pace, and if a ten-second spike generates a million events, they sit buffered in Kinesis and get drained over the next few minutes without any client noticing:
def writer_handler(event, context):
# Consume the data pump at the database's pace, in batches.
with dynamodb.batch_writer(table="Orders") as batch:
for record in event["Records"]:
batch.put_item(Item=decode(record))
The consequence of that separation is what defines the architecture: the write spike hits Redis and the Kinesis buffer, which handle volume with room to spare, and never DynamoDB synchronously. The database stops being the bottleneck because it stopped being in the request’s path.
I talked about the write path, but at peak the bigger volume is usually reads: millions of people checking whether there are still tickets. There the space works in your favor for free, the read is served straight from Redis, which is exactly what it’s good at, and availability never touches the database on the happy path. The thing to watch is a mass cache miss, which lands on the rehydration problem I’ll get to in the downsides.
One detail that isn’t optional: data collision. In the ticket example, you need to guarantee that fifty thousand units don’t become fifty thousand and one. In the classic architecture, the data grid handled this among the processing units. In serverless, it centralizes on Redis, and you solve it with Redis’s primitives, atomic operations, Lua scripts, or optimistic locking with WATCH. The inventory decrement has to be atomic in the space, not in the database. If you forget this, the architecture works beautifully until the day of the real peak, and then oversell becomes a legal problem.
And there’s a symmetry trap here. You just took the hot key out of DynamoDB and threw it into Redis, which is single-threaded per shard. A SKU that went viral serializes all the decrements onto a single core, and cluster mode doesn’t slice a single key across nodes, it lives in one slot. A Redis primary handles far more than DynamoDB’s thousand writes per second, so the pain is smaller, but in the most extreme case the solution is the same idea as write coalescing, just on the read side: shard the counter, split inventory:{sku} into N sub-keys, decrement a random one, and sum them at read time.
What’s not in the diagram: idempotency, connections, and observability
There are three things the pretty diagram hides that decide whether this works on the day of the peak. All three take projects down.
The first is idempotency. Both SQS and Kinesis deliver at least once, so your writer will reprocess a message, it’s a question of when, not if. The naive batch.put_item in the example replicates writes. What saves you here is that DynamoDB in this architecture is a projection, not the source of truth, Redis already has the authoritative count. So a PutItem with a deterministic key, the order id or the event id, is naturally idempotent: reapplying it comes out the same. What you can’t do is an additive update on the database, summing or incrementing, without a deduplication key, because then every redelivery adds again and the projection lies. And on Kinesis, configure an on-failure destination and bisect on error, otherwise a poisoned batch jams the whole shard and the pump stops with nobody watching.
The second is connections, and it’s the failure most specific to doing this in serverless. ElastiCache and MemoryDB live inside a VPC, so the Lambda has to be in the VPC to reach the space, and the Redis client has to be instantiated outside the handler, at module scope, to be reused across warm invocations. The real problem shows up at peak: Lambda scales to hundreds or thousands of simultaneous execution environments, and each one opens a connection to Redis. That’s a connection storm on top of an endpoint that has a client limit, and it’s exactly the kind of failure that doesn’t happen in the classic architecture, where the grid lives inside the process. The good news is that the old terror of Lambda cold starts in a VPC is over: since Hyperplane ENIs the penalty is sub-second, not the ten seconds of the old days.
The third is observability. An asynchronous pipeline has no synchronous trace linking the client’s request to the final write in the database. The request comes in through the API, passes through Redis, is decoupled into the buffer, and is persisted seconds later by another Lambda. When something jams at peak, you don’t have a stack trace, you have loose pieces. Instrument with X-Ray, propagating context manually through the buffer and, more importantly, alarm on the Kinesis iterator age or the SQS age of oldest message. That’s the number that warns you persistence is falling behind before the client notices.
The advantages of doing this in serverless
The biggest advantage is that the hardest part of space-based architecture disappears. The deployment manager, the orchestration of spinning processing units up and down with load, is exactly what Lambda and the managed services deliver for free. You don’t operate a Hazelcast, Ignite, or GemFire cluster, you don’t size a fleet, you don’t write elasticity logic. In the traditional architecture, that’s months of engineering and a permanent source of incidents. Here it’s configuration.
Cost comes along with it. The classic version is expensive because you keep a grid of memory-heavy machines running all year for a peak that happens over two or three days. Serverless flips that: you pay for the Lambdas per use, scale to near zero between peaks, and only Redis stays always on. For a business whose critical event is seasonal, that’s real money at the end of the month.
And there’s the operational side, which for me is what weighs most. With the database out of the critical path, the hardest component in your system to scale stops being the one that decides your availability at the worst moment. I promise you, sleeping easy the night before a whole-stadium ticket sale is worth more than any latency benchmark.
The downsides, which are real
The first downside is latency, the cost I promised to detail earlier. The in-process replicated cache, the architecture’s signature feature, doesn’t exist. Every access to the space is a network hop to Redis. You go from in-process access in nanoseconds to a network round-trip that, with ElastiCache Serverless, lands in the sub-millisecond range. Fast, more than enough for the vast majority of cases, but it’s not the same thing, and if your use case genuinely needs in-process access, serverless isn’t the place.
The second is cruel in its irony: cold start. You’re designing for the peak, and the peak is exactly when Lambda has to spin up hundreds of new executions, each paying the initialization latency. Provisioned concurrency solves it, but it costs money and undercuts part of the scale-to-zero benefit. Now, in most cases that justify this architecture the peak is scheduled, the sale opens at ten. That changes the game: you pre-warm. You bring up scheduled provisioned concurrency and preload the inventory into Redis ahead of time, instead of discovering the cold start in the first second of the sale. And watch out for the inverse effect on rehydration: if the space goes down in the middle of the peak, all the Lambdas cache-miss at the same time and hammer DynamoDB to repopulate, recreating exactly the overload the architecture exists to avoid. The protection is single-flight, one Lambda rehydrates while the others wait, not a stampede.
The third is consistency, and with it comes the risk of data loss. Persistence is asynchronous by design, so the database is always behind the space. Any consumer that reads straight from DynamoDB expecting the last write will read stale data. Eventual consistency stops being a detail and becomes a design premise: every downstream component has to be designed knowing the database lags behind reality. And if you use the space as a cache, which is the typical use in serverless mode, when it dies before the pump drains you lose the window of writes that haven’t been persisted yet, typically a few seconds in the worst case. What you can’t do is treat a cache as the source of truth thinking it’s durable. Jepsen has shown crystal-clearly that in-memory grids like Hazelcast, under a network partition, lose and duplicate data in ways you don’t want to discover in production. If the data is financial and can’t be lost, you need real durability in the space itself: MemoryDB has always been durable, and ElastiCache for Valkey gained a durable mode recently, but in nodes, not in serverless. The price of both is the same, slower writes and an always-on component.
The fourth is that the space isn’t truly serverless. Even with ElastiCache serverless, you have an always-on component, with a memory limit and an associated cost, in the middle of an architecture you chose because of elasticity. There isn’t, today, a genuinely serverless in-memory grid with the same semantics as the classic grid. It’s a seam, and seams have a cost.
And the fifth, the one that matters most: complexity. Richards and Ford give this architecture the lowest simplicity score in the book, and serverless doesn’t fix that. You now have API Gateway, processing Lambdas, Redis, Kinesis, writer Lambdas, DynamoDB, and rehydration logic, all for a pattern that’s only justified under a very specific load profile. Testing it is another nightmare: the architecture exists for the peak, and reproducing the peak in a test environment is expensive and hard. You find out whether you got it right on the day you can’t get it wrong.
The alternative a lot of people ignore: attack the spike at admission
Before talking about when not to use it, I need to put on the table the alternative a lot of people forget. Space-based architecture attacks the spike at absorption: it lets everyone in and takes the hit in memory. There’s another school that attacks the spike at admission: it doesn’t let everyone in at once. It’s the virtual waiting room, the queue that services like Cloudflare Waiting Room and Queue-it implement.
The idea is direct. Instead of sizing the system for two million simultaneous people, you admit people at a pace the system can take, and the rest wait in a fair queue. And, as unexciting as it sounds, this is what most of the big ticket-selling platforms actually do. It’s dramatically simpler than building an in-memory data grid, there’s no risk of data loss in the core because it’s admission control and not storage, and in most cases it’s a managed product you turn on and configure.
The difference in applicability is what matters: a waiting room works when the spike is people, and you can make people wait. When the spike is machines, IoT telemetry, real-time bidding, events you can’t put in a waiting queue because nobody’s watching, then in-memory absorption is the right answer again. For ticket sales, in practice, I strongly recommend evaluating the waiting room before anything more complex.
When not to use it, which is almost always
I’ll be categorical, because it’s where I see people get it wrong most: the overwhelming majority of systems will never need this, and building it anyway is paying the most expensive bill in the catalog for a problem you don’t have. If your load is predictable or moderate, DynamoDB on-demand with a plain cache-aside already scales beautifully and is ten times simpler. You don’t need a data pump, you don’t need to rehydrate a grid, you don’t need to deal with collision centralized on Redis. You need a database that scales, and AWS gives you that out of the box.
But there’s one exception that changes the bar, and it’s exactly where the principle stops being a luxury and becomes a necessity: the hot key. DynamoDB has a per-partition limit of a thousand write units per second, and that limit is hard, on-demand mode doesn’t lift it. It doesn’t matter how much capacity the table has. If your peak concentrates on a single item, the inventory for one specific show, a SKU that went viral, you throttle on that partition while the rest of the table sits idle. This is exactly where “just turn on on-demand” fails. And the solution, absorbing the decrement in Redis with an atomic operation and write-coalescing to the database, is the principle of space-based architecture reappearing, even if nobody calls it by that name. So the right question isn’t “is my load high?”. It’s “does my peak concentrate on a single key?”. If it does, you’re going to inherit the principle whether you want to or not. If it’s well distributed, the managed database scales and you don’t need any of this.
This connects directly to something I’ve argued before about thinking from first principles instead of copying patterns: the mistake isn’t technical, it’s in the reasoning. Adopting the most complex architecture in the catalog because it’s elegant, or because some big tech uses it, without having the load profile that justifies it, is the same as doing mise en place for a thousand plates on a night when thirty people will walk in. You prepped the whole restaurant for a rush that isn’t coming, and you pay the cost of that prep every single day. Decompose the problem first. Ask whether you really have an unpredictable, concentrated write spike that takes the database down, or whether you just have a badly configured cache. I promise you, in nine out of ten cases, it’s the second.
Space-based architecture makes sense when you’ve proven, with real load or an honest projection, that the database is the bottleneck and that the spike, concentrated on a single point, is the shape of the problem. Concert tickets, auctions, live betting, absurd-scale flash sales. Outside of that, the complexity it adds costs more than the problem it solves.
Wrapping up
Space-based architecture solves a specific, real problem: the unpredictable write spike that no application auto-scaling saves you from, because the bottleneck is the database. It does this by taking the database out of the critical path, serving the transaction in memory and persisting asynchronously. In serverless on AWS, you don’t implement the literal version, with its long-lived processing units and in-process replicated grid; you inherit the principle and let the platform handle elasticity, with ElastiCache as the space, Lambda as the processing unit, Kinesis as the data pump, and DynamoDB as the asynchronous destination. You gain elasticity and cost, you lose in-process access and you inherit eventual consistency and complexity.
The concrete next step, before designing any of this, is to measure. Run a load test on your current design and find out where the database actually breaks, and under what shape of load. And test the right thing: don’t spread the load across a thousand keys, concentrate it on a single key, which is where it really breaks, and ramp concurrency up abruptly to provoke the connection storm. Watch the DynamoDB throttles, Redis connections and CPU, the buffer’s iterator age. Spread-out, gentle load passes the test and fails the sale. If the database handles your real peak, you don’t need space-based architecture, and knowing that has already saved you months. If it breaks, and breaks in the specific way I described, then it’s worth building a small POC with API Gateway, Lambda, ElastiCache serverless, Kinesis, and DynamoDB, and measuring again. The right architecture never comes from the prettiest diagram. It comes from the number you measured.